アーキテクチャの概要¶
このドキュメントでは, Scrapyのアーキテクチャとそのコンポーネントがどのように相互作用するかについて説明します.
概要¶
次の図は, Scrapy アーキテクチャの概要とそのコンポーネントと, システム内部で実行されるデータフローの概要を示しています(緑色の矢印). コンポーネントの簡単な説明は, それらの詳細な情報については, 以下のリンクを参照してください. データフローも以下で説明します.
データフロー¶
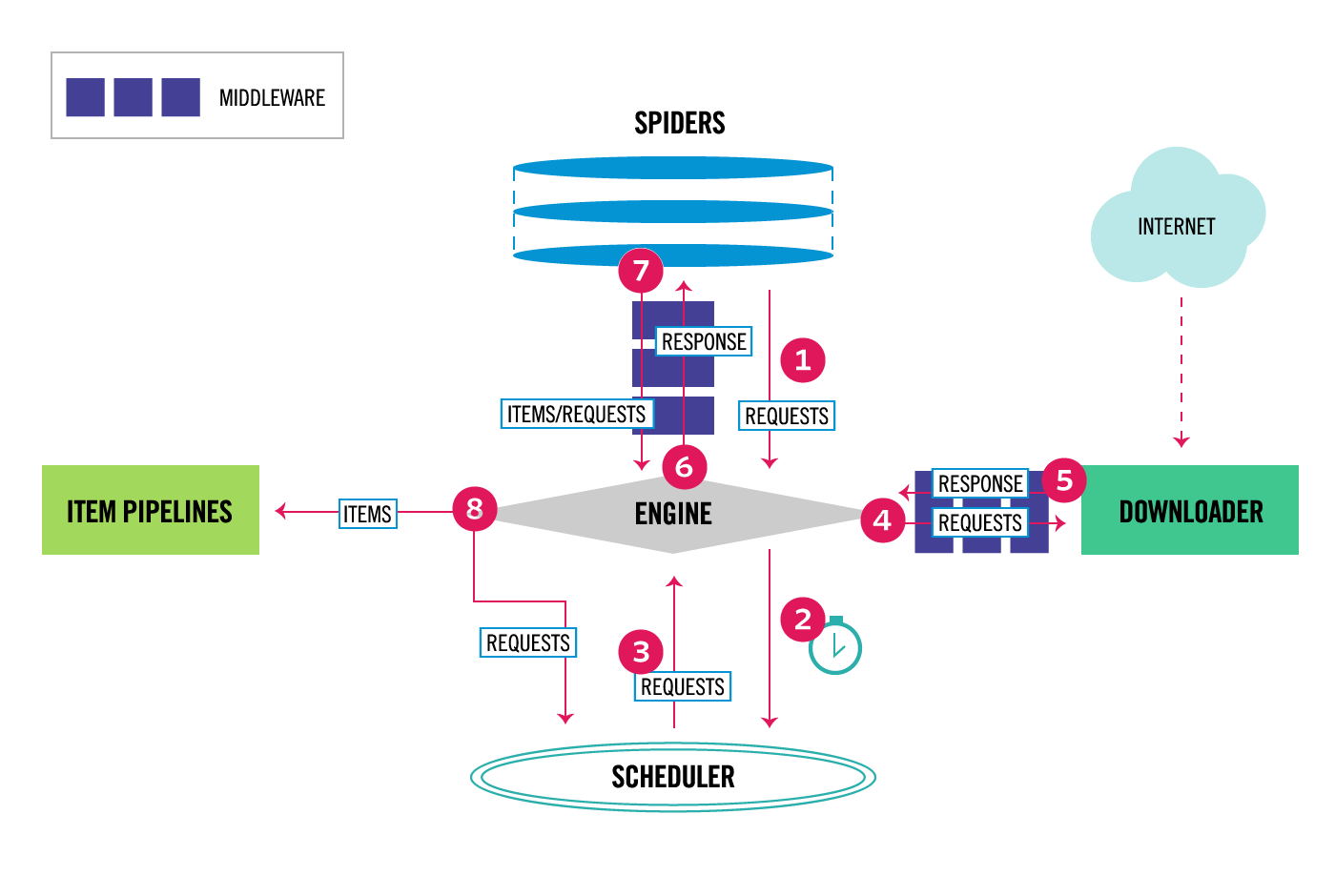
Scrapy のデータフローは実行エンジンによって制御され, 以下のようになります:
- Engine は, Spider からクロールする最初のリクエストを取得します.
- Engine は, Scheduler 内のリクエストをスケジュールし, 次にクロールするリクエストを要求します.
- Scheduler は, 次のリクエストを Engine に渡します.
- Engine は, Downloader Middlewares
を経由して Downloader にリクエストを送信します
(
process_request()を参照してください). - ページのダウンロードが終了すると,
Downloader はそのページでレスポンスを生成し,
Downloader Middlewares
(
process_response()を参照してください) を経由して Engine に送信します. - Engine は, レスポンスを Downloader
から受信し, Spider Middleware
(
process_spider_input()を参照してください) を経由する処理のために Spider に送信します. - Spider はレスポンスを処理し,
Spider Middleware
(
process_spider_output()を参照してください) を経由して, 収集したアイテムと新しいリクエストを Engine に返します. - The Engine は, 処理されたアイテムを Item Pipelines に渡し, 処理されたリクエストを Scheduler に渡した後, 次のクロールリクエストを要求します.
- このプロセスは, Scheduler からの要求がなくなるまで(ステップ1から)繰り返されます.
コンポーネント¶
Scrapy エンジン¶
エンジンは, システムのすべてのコンポーネント間のデータフローを制御し, 特定のアクションが発生したときにイベントをトリガーします. 詳細については, 上記の データフロー のセクションを参照してください.
スケジューラー¶
スケジューラは, エンジンからリクエストを受信し, エンジンが要求したときに後で(エンジンにも)それらを供給するためにそれらのキューを実行します.
ダウンローダー¶
ダウンローダーは, Web ページを取得してエンジンに供給し, そのエンジンをスパイダーにフィードします.
アイテムパイプライン¶
アイテムパイプラインは, アイテムがスパイダーによって抽出されるとアイテムの処理を行います. 典型的なタスクには, クレンジング, 検証, 永続性(アイテムをデータベースに格納するなど)が含まれます. 詳細は, アイテムパイプライン を参照してください.
ダウンローダーミドルウェア¶
ダウンローダーミドルウェアは, エンジンとダウンローダーの間に位置し, エンジンからダウンローダーに渡されたリクエストと, ダウンローダーからエンジンに渡すレスポンスを処理する特定のフックです.
次のいずれかを実行する必要がある場合は, ダウンローダーミドルウェアを使用します:
- ダウンローダに送信される直前のリクエスト(つまり, Scrapy がリクエストをウェブサイトに送信する直前)を処理する
- 受信したレスポンスをスパイダーに渡す前に変更する
- 受け取ったレスポンスをスパイダーに渡す代わりに新しいリクエストを送信する
- ウェブページを取得せずにスパイダーにレスポンスを渡す
- いくつかのリクエストを実行しない
詳細については, ダウンローダーミドルウェア を参照してください.
スパイダーミドルウェア¶
スパイダーミドルウェアは, エンジンとスパイダーの間に位置し, スパイダーの入力(レスポンス)と出力(アイテムとリクエスト)を処理する特定のフックです.
次のいずれかを実行する必要がある場合は, スパイダーミドルウェアを使用します:
- スパイダーコールバックの後処理出力 - リクエストまたはアイテムの変更/追加/削除
- start_requests の後処理
- スパイダーの例外処理
- レスポンスの内容に基づいてリクエストの一部をコールバックする代わりにerrbackを呼び出す.
詳細については, スパイダーミドルウェア を参照してください.